
Data migrations can vary significantly in complexity and strategy. Unique file formats, abnormal delimiters, and non-standard data structure can take what should be a simple process and turn it into a significant task as a team may be trying to deploy a new solution. We recently had a parsing puzzle rather intricate data export that needed to be processed and imported that forced us to take some time to study the file and develop a plan for sanitizing the data. While each case is unique, we believe it may benefit others in our community to observe our approach and perhaps apply it to solve a similar task or use it as a training exercise for those new to the FileMaker platform.
Data | Initial Challenges

At first glance, the data is pretty straightforward — standard contact data with ID, name, address, and so forth; however, slight inconsistencies in patterns and data placement required a more structured approach to analyze and separate the data. Notice, for example, that some addresses have four lines of data, some have three. A P.O. Box may be on the second line, or perhaps on the third. It may be abbreviated differently. There were a dozen or more such exceptions within the data set.
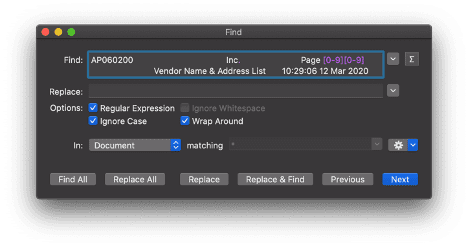
Our first goal was to determine how to divide this vast “blob” of data into individual entities or records. We discovered that all of the individual record data was contained in a repeatable pattern of five lines per record. This consistent pattern made the process relatively straightforward, except the document had headers sprinkled throughout the file. Our first thought was to use a simple find-and-replace, but there was a page number variable that made this impossible. We decided to use a text editor (my personal preference being TextMate) to do a find-and-replace using a regular expression. Using a regular expression allows for variance within the find criteria. It ended up looking like this.
Once the data was in a format that enabled a repeatable pattern for record separation, it was time to move our work into FileMaker. First, we created a simple looping script to parse the block of data into individual records and store that record data into a variable, to be passed to a sub-script for further parsing.
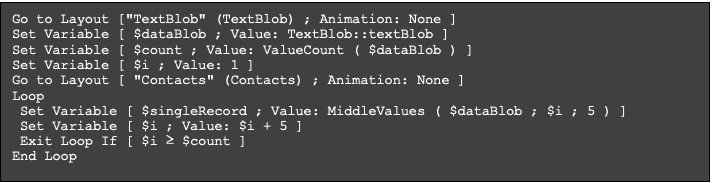
Record | Parsing individual fields
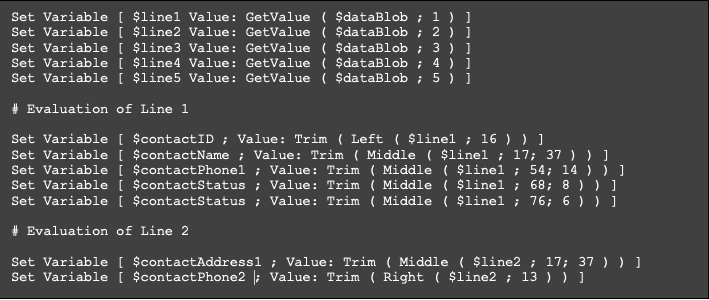
The next hurdle was to separate the individual field data from each record. Viewing the data in a text editor with a monospace font allowed us to recognize that there were set character counts in each respective field space. Based on this observation, we then started the process of separating the data into individual lines and carefully figuring out the number of characters contained in each area on the line. Using text-formatting functions, we started the process of isolating the individual pieces of data and storing those values in variables.
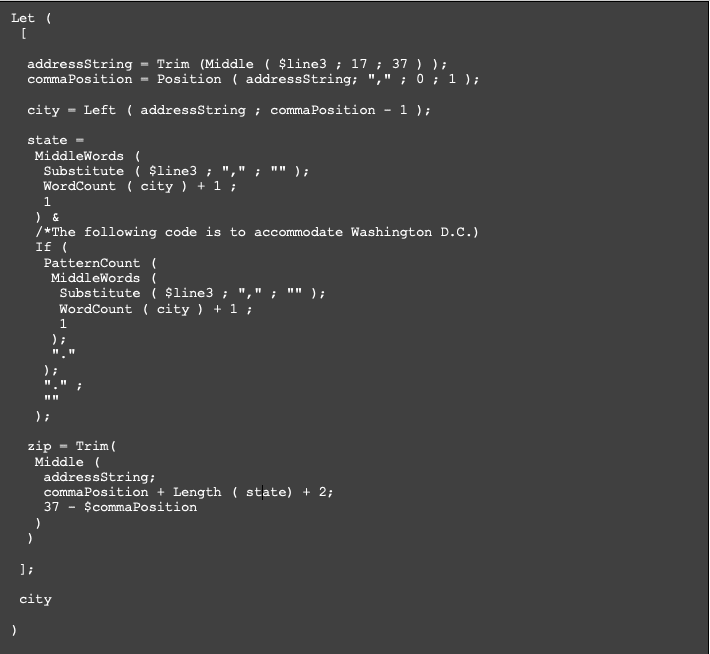
Separating the first and second lines of data could be accomplished using the Left, Middle, Right, and Trim functions. The next line required some conditional logic since the data could be either the city, state, and zip or the second address line. Also, consideration needed to be made to allow for cities longer than a single word, states that were abbreviated, and zip codes that included additional integers. To handle the conditional nature of the data, we added simple if statements to scan for data patterns within the line. Once the data type was determined, we broke out the line into separate variables using a few different functions than those used for the first two lines. Here is how to specify the variable value for city, state, and zip from the string using a “Let” statement.
Wrapping up the parsing the line four was a near mirror of the structure for line four with the exception being the only data that could be present was either the city, the state, or the zip code. Once all of the variables were defined, the final step in the process was to save all the parsed data into a new record.
Training | Putting it into practice
One exciting aspect of this particular assignment was that we had the opportunity to work through this process with Alex, one of our brand-new apprentices. He had no prior experience with FileMaker, but we used this task as a training tool to get him acquainted with scripting and a variety of text-based functions.
“This project jumpstarted my learning experience and threw me right into the deep end of scripting. The day following the completion of the first data parsing task, I was handed another similar data parsing assignment. The process on how to solve the issues in the data set remained the same but the spacing and the variables in the different lines were all different now. This was a perfect opportunity to apply everything that I had spent the last several days learning and use it to solve my very own real problem.
I was able to come up with something resembling a finished product all on my own by applying the same logic used in our first project but tweaking all of the pieces to work for this new scenario. I was incredibly proud of myself to be able to pull this project off.” – Alex Tooly
Conclusion
There are a variety of approaches that could be used to tackle this type of problem. One suggestion I would have for both novice and experienced FileMaker developers is to periodically take the time to review the tools you have available. This past summer, in preparation for the last certification exam, I reviewed the entire library of functions available within FileMaker and was amazed at how many I had either forgotten about or didn’t fully understand. Doing this really helped me evaluate and optimize data workflows in my personal development process. I would encourage all of us to keep striving to learn, to improve, and to better ourselves both personally and professionally.
“The capacity to learn is a gift; the ability to learn is a skill; the willingness to learn is a choice.” – Brian Herbert
We often speak with clients about pulling data into newly built FileMaker solutions. We hope this simple example demonstrates all that goes into “a simple import”. Sure, you’ve got the data in a spreadsheet, but as we hope we’ve illustrated, that can present an extremely time-consuming programming challenge.
Please utilize the sample files below to review the full implementation of the concepts discussed above. We hope this is a help to those getting started with FileMaker data parsing.

Built with you in mind
Speak to one of our expert consultants about making sense of your data today. During
this free consultation, we'll address your questions, learn more about your business, and
make some immediate recommendations.